There are lots of ways to accidentally spend too much money on AWS, and one of the easiest ways is by carelessly transferring data. As of writing, AWS charges the following rates for data transfer:
-
Data transfer from AWS to the public Internet ranges from $0.09/GB in
us-east-1(N. Virginia) to $0.154/GB inaf-south-1(Cape Town). Therefore a single terabyte of data transfer will run you a cool $90 - $154. -
Data transfer from one AWS region to another - e.g. if you were to transfer data from
us-east-1to any other region - ranges from $0.02/GB inus-east-1to $0.147/GB inaf-south-1(more than seven times as much!). Therefore a single terabyte of transferred data that never leaves AWS's network will run you $20 - $147.
In both of these transfers, you're only paying for egress fees - i.e. you're paying for data that leaves AWS regions, and not for incoming data. But now we'll look at one of the trickier data transfer rates:
- Data transfer between availability zones in the same AWS region - e.g. from
us-east-1atous-east-1b- will cost you $0.01/GB in each direction. This pricing is the same in all regions. Therefore a single terabyte of transferred data between two same-region availability zones will cost you $10 for the egress and $10 for the ingress, for a total of $20.
These prices are similar between all major cloud providers. Data transfer prices easily add up, and are an extremely high-margin source of profit for cloud providers - so high-margin that Cloudflare has introduced its competing R2 storage whose primary competitive distinction is a zero egress fee, along with publishing some fairly strong rhetoric lambasting AWS for its egress charges (conveniently failing to point out that Cloudflare's whole business model is uniquely poised to competitively offer zero egress fees in a way that AWS is not).
Tip
This is a good time to mention AWS PrivateLink and VPC endpoints. You might assume that if you set
up an EC2 instance in us-east-1 and transfer a terabyte from the instance to another region,
you'll pay the $20 cross-region data transfer charge. But by default, you might very well end up
paying the $90 internet egress data transfer charge - e.g. if you transfer the data to a public
S3 bucket in another region, you'll effectively be transferring data over the internet.
AWS PrivateLink and VPC endpoints allow you to ensure that data between regions never leaves AWS's network - useful not only in terms of pricing but also in terms of security. These features are not free, and come with their own limitations and pricing subtleties, but that's beyond the scope of this blog post - AWS has a couple of nice posts on the subject, and so does Vantage.
It's a common creed of AWS that setting resources up in multiple availability zones is best practice for ensuring reliability and availability. But this best practice easily opens up the door to funneling money into a furnace of cross-AZ costs - any application that involves sending data between resources in different availability zones will incur such charges.
Can we have our cake and eat it too? Can we set up cross-AZ infrastructure but avoid paying cross-AZ data transfer costs?
Sidestepping Data Transfer Costs with S3
S3 has an important characteristic - most storage classes in S3 store their buckets in region
granularity rather than availability zone granularity. This means that you don't upload data to
a us-east-1a or a us-east-1b bucket, you upload data to a us-east-1 bucket. Behind the
scenes, AWS replicates this data in a minimum of three availability zones in the region - which is
one of the reasons why S3 has such exceptionally high durability and availability.
Note
There are two storage classes - S3 One Zone-Infrequent Access and the newly introduced S3 Express
One Zone - that only store data in a single availability zone. You pay less for storage, but at a
cost of availability - for instance, in us-east-1, S3 One Zone-Infrequent Access costs $0.01/GB
as opposed to S3 Infrequent Access which costs $0.0125/GB, but it is designed for 99.5%
availability as opposed to 99.99%.
This means that data in a standard S3 bucket is "equally" available to all AWS availability zones
in its region - it doesn't make a difference to S3 if you download data from us-east-1a or
us-east-1b.
But wait - S3 has another important characteristic. For the standard storage class, downloading data from S3 is free - it only incurs standard data transfer charges if you're downloading it between regions or to the public Internet. Moreover, uploading to S3 - in any storage class - is also free! (For the data transfer - the S3 API requests you make will cost you money, but relatively little)
So let's say I want to transfer 1TB between two EC2 instances in us-east-1a and us-east-1b. We
saw above that if I transfer the data directly, it will cost me $20. But what if I upload the data
to S3 from one instance and then download it from the other?
The upload will be free. The download will be free. The S3 storage will not be free, and in
us-east-1 costs $0.023/GB, or $23/TB, every month. This is charged on hour granularity, and we
can design our upload/download such that no data persists in S3 for more than an hour. Let's say
there are 720 hours in a month, this means we'll have to pay 1/720 of $23, or about $0.03. (We
need to remember to delete the storage when we're done!)
So instead of paying $20, this data transfer will cost only $0.03 - pretty cool! If we want to express these savings mathematically - assuming sub-hour data transfer rates, we've reduced our data transfer charges from $0.02/GB ($0.01 for egress and $0.01 for ingress) to $0.000032/GB - just 0.15% (i.e. 15% of 1%) of the original charge. This gives us near-free cross-AZ data transfer costs. As an extreme example, transferring 1PB of data with this method will set you back about $32, as opposed to $20,000 with the standard way.
But wait, there's more! S3 has another important characteristic - it is infinitely scalable. So this method makes it very convenient to replicate data from one AZ to as many instances as we want in another AZ - thousands of instances in the second AZ could download the same S3 object, and it should take up the same time as if just a single instance was downloading it. The S3 storage cost will remain constant, and the download cost will remain free. This is pretty cool too.
Warning
S3 has another important characteristic - no single object can be more than 5TB. So if you're using
this method to transfer files bigger than 5TB, they need to be fragmented. Moreover, no single
upload can be more than 5GB - you'll need to use multi-part uploads if your files are bigger than
this (aws s3 cp takes care of this automatically behind the scenes).
Demo
Let's see this in action and be amazed. When I first thought of this method, the cost savings seemed too good to be true - even though all the fundamentals behind the method were solid, I didn't believe it until I saw it in the Cost Explorer.
I want to start with clean AWS accounts so that there's no noise when we're examining the pricing. As such, I created two accounts for each part of the demo:

In each account, we will set up two EC2 instances - one in us-east-1a and another in
us-east-1b. In each account, we'll place both instances in a public subnet so we can easily
SSH into them. And in each account, we'll generate a random 1TB file in the us-east-1a instance,
and our goal will be to transfer it to the us-east-1b instance.
We'll run these two experiments:
-
In the first experiment, we'll place both instances in a VPC with private subnets in each of the two availability zones. We'll set up a netcat server on the
us-east-1binstance - on the interface connected to the private subnet. Theus-east-1ainstance will then transfer the 1TB file to theus-east-1binstance. -
In the second experiment, we'll place both instances in a VPC that has an S3 Gateway endpoint, we'll create an S3 bucket, and the
us-east-1ainstance will upload the 1TB file to the bucket. Once this is done, theus-east-1binstance will download the 1TB file (and then delete it!).
Warning
We should note that AWS's free tier might slightly affect the results of the experiment - I haven't used up my S3 free tier, which is 5GB-months for 12 months. I'm not entirely sure how to artificially consume the free tier without waiting 8+ hours to be sure that it won't affect the billing of the new AWS accounts, and I'm not entirely thrilled about taking an 8+ hour break from writing this blog post, especially since it won't matter much; 5GB-months is less than 1TB-hours (but not by much), and the storage cost we're expecting to see in the S3 Data Transfer account is miniscule as it is.
In both experiments, we'll have transferred 1TB from us-east-1a to us-east-1b. After this,
we'll wait for AWS's Cost Explorer to update with the incurred costs to see that this method
really works.
The experiments themselves are fairly straightforward, so they're toggled away for brevity:
Results
A few hours later, Cost Explorer is updated with the billing data. Our control experiment of a standard data transfer - which we expected to cost $20 - indeed ended up costing $21.49 (I accidentally stopped the transfer at one point and had to restart it, accounting for some of the extra cost - also the created file was technically 1024GB so the base price was $20.48):
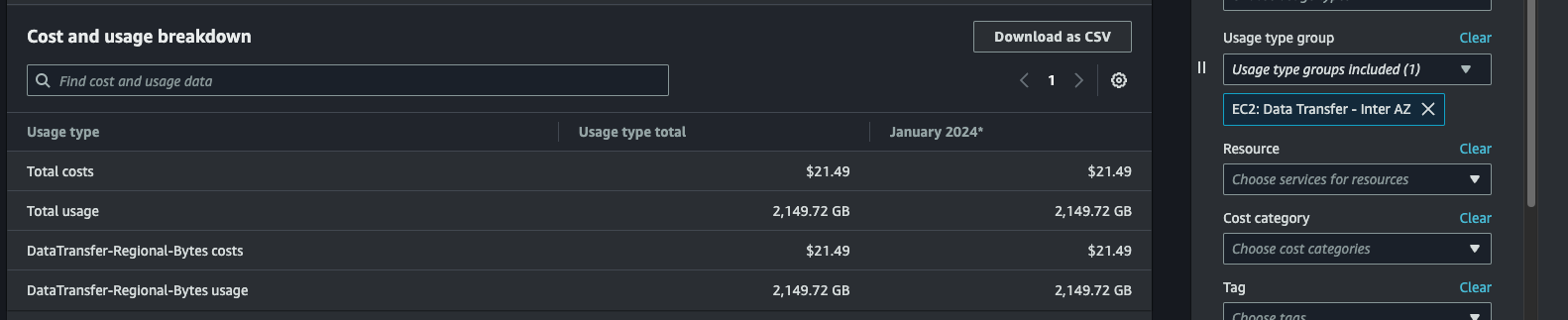
But the real experiment is the S3-based data transfer, which we expected to cost only a few cents in storage costs. And... 🥁🥁🥁:
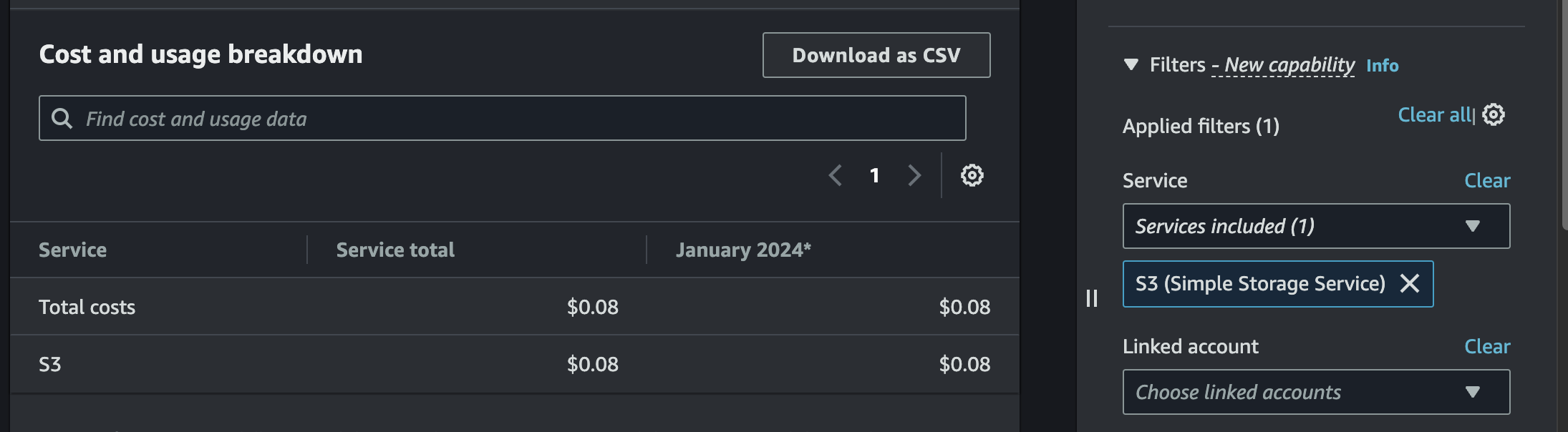
Only eight cents!!! Let's drill down and see how this S3 storage cost breaks down, and let's also expand our filter so we can be convinced that there are no data transfer charges:
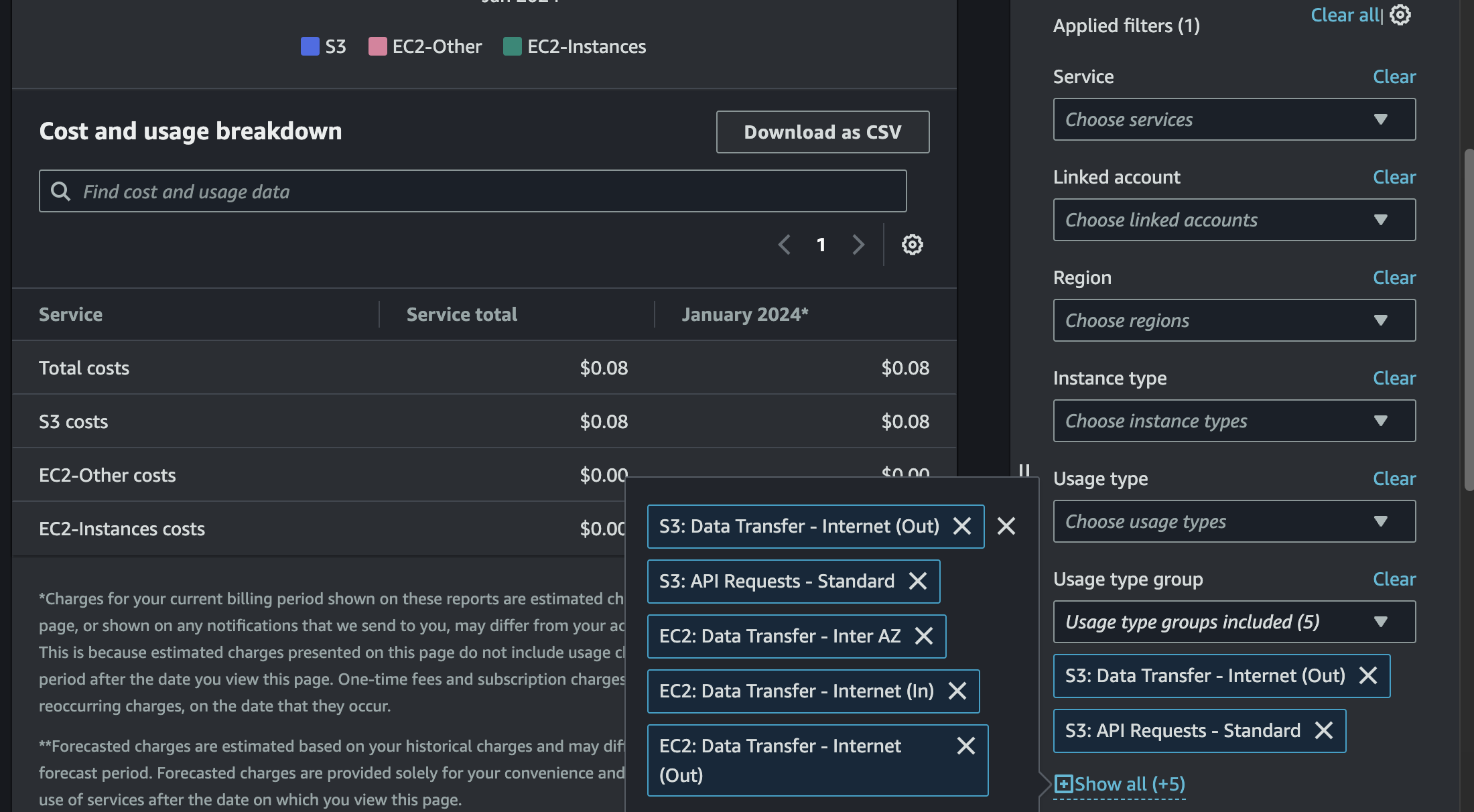
And indeed, we can see that there are no data transfer costs!! But, something's weird - the only S3 usage types available have nothing to do with storage... Let's filter down to S3 and group by usage type:
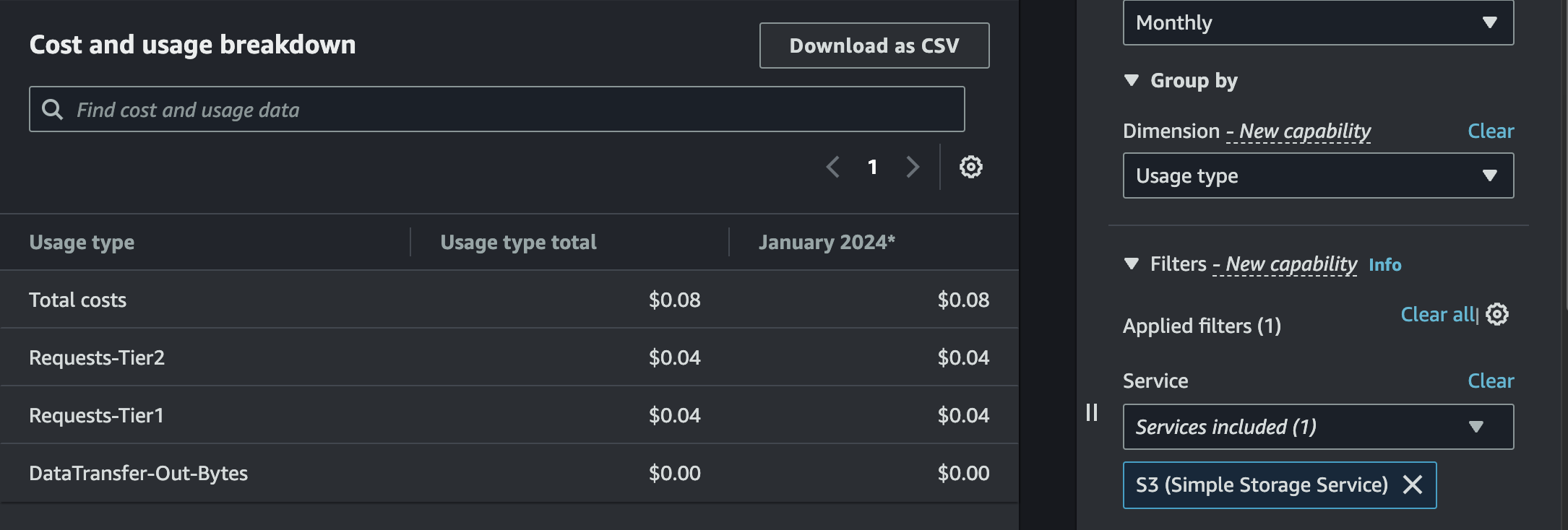
Note
The above paragraph turned out to be inaccurate - as I learned later on, S3 storage costs are reported on daily granularities per-bucket. It just takes long for Cost Explorer to update with this data than it does with other types of charges. As expected, the reported storage costs were only pennies - and my free tier was entirely consumed.
Thanks to Dieter Matzion of the FinOps community for alerting me to this possibility.
Conclusions
Behind the scenes, AWS replicates S3 data between availability zones for you - whatever this might cost AWS is hidden away in the storage costs you pay for your data. So at its most fundamental level, this method is unlocking free cross-AZ costs - because you've effectively already paid for the cross-AZ cost when you uploaded your data to S3! Indeed, if you were to leave your data stored in S3, you'd end up paying significantly more than the cross-AZ cost - but by deleting it immediately after transferring it, you unlock the 99% savings we were going for.
There are some obvious drawbacks to this method: It's not a drop-in replacement for existing data transfer code, and it can have much higher latency than direct network connections. But if cost is your primary concern, this is an effective way of reducing costs by over 99%.
I really hope you find this method useful, and I think it goes to show just how far you can take cost savings in AWS - there are so many services with so much functionality and so many price points that there's almost always room for more savings.
This blog post sparked some interesting discourse in: